
When implementing search engine optimizations (SEO) and making beneficial updates to your website, you may inadvertently create other issues in the process. One of those issues could be duplicate content, which, when left unaddressed, can harm your SEO value and search engine rankings over time.
In this article, you’ll learn how to find duplicate content, what commonly causes duplicate content, and how to remove it from your site.
Read through or head over to the section you want to learn more about:
Impact on SEO and Rankings
How to Find Duplicate Content
Causes of Duplicate Content
Ways to Remove Duplicate Content
What is Duplicate Content?
Duplicate content occurs when an already existing webpage can be found through multiple URLs. When there is duplicate content on a site, search engines can get confused by which URL is the original, or preferred, piece of content.

Impact on SEO and Rankings
Due to the confusion duplicate content causes search engine robots, any rankings, link equity, and page authority the page receives can end up being split between the duplicated URLs. This happens because search engine robots are left to choose the web page they think should rank for a particular keyword, and do not always pick the same URL every time. This causes each URL variation to receive different links, page authority scores, and ranking power.
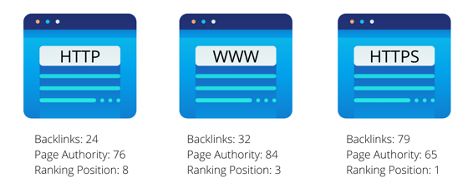 Over the years, there has been a lot of confusion around if Google (and other search engines) penalize sites with duplicate content. Don’t worry, they don’t penalize sites!
Over the years, there has been a lot of confusion around if Google (and other search engines) penalize sites with duplicate content. Don’t worry, they don’t penalize sites!
Google understands that the vast majority of duplicate content is not created intentionally—50% of websites have duplicate content issues! However, because Google aims to show a diverse set of websites in search results, as opposed to the same piece of content twice, their crawl bots are forced to choose which version to rank. This choice is what indirectly harms your webpage’s SEO and rankings.
Duplicate content on your site can lead to three main issues:
- Lower search results rankings
- Poor user experience
- Decreased organic traffic
To remove duplicate content from your website and prevent further SEO harm, you first need to find what pages are duplicated.
How to Find Duplicate Content
There are several ways you can find duplicate content on your site. Here are three free ways you can find duplicate content, keep track of which pages have multiple URLs, and discover what issues are causing duplicate content to appear across your site. This will come in handy when you remove the duplicate pages.
Google Search Console
Google Search Console is a powerful free tool at your disposal. Setting up your Google Search Console for SEO will help provide visibility into your webpages’ performance in search results. Using the Search results tab under Performance, you can find URLs that may be causing duplicate content issues.
Look out for these common issues:
- HTTP and HTTPS versions of the same URL
- www and non-www versions of the same URL
- URLs with and without trailing slash “/”
- URLs with and without query parameters
- URLs with and without capitalizations
- Long-tail queries with multiple pages ranking
Here is an example of what you might find:
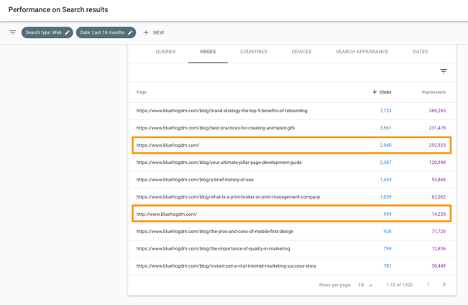
From the image above, you can see the HTTP and the HTTPS version of Blue Frog’s homepage are both ranking in search results and receiving clicks.
http://www.bluefrogdm.com/ https://www.bluefrogdm.com/
Keep track of the URLs you discover with duplication issues. We will go over ways to fix them later!
“Site:” Search
By heading over to Google search and typing in “site:” followed by your website URL, you can see all of the pages that Google has indexed and have the potential to rank in search results.
Here is what appears when you type in “site:bluefrogdm.com/blog” into the Google search bar:
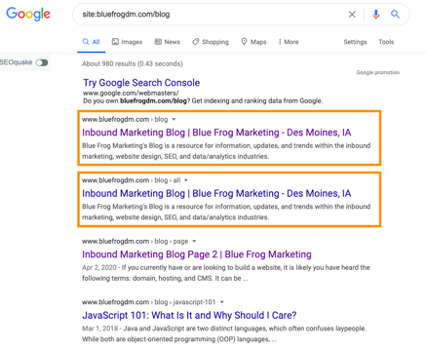
As you can see, there are two nearly identical pages for the Blue Frog blog that appear. This is an important thing to note: while these pages are not technically duplicate pages, they contain the same title tag and meta description, which can lead to keyword cannibalization and ranking competition between the two pages, similar issues that duplicate pages run into.
Duplicate Content Checker
SEO Review Tools created this free duplicate content checker to help websites combat content scraping. By inputting your URL into their checker tool, you can get an overview of external and internal URLs that duplicate the inputted URL.
Here is what was found when I plugged “https://www.bluefrogdm.com/” into the checker:
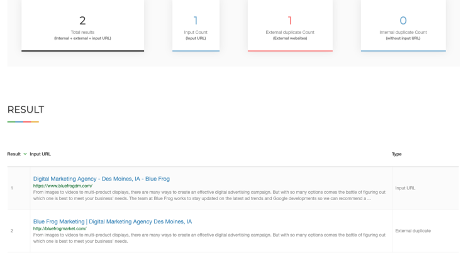
Discovering external duplicate content is very important. External duplicate content can occur when another website domain “steals” your site’s content, also known as content scraping. When discovered, you can submit a removal request to Google and have the duplicated page taken down.
Causes of Duplicate Content
There are many reasons duplicate content can be created (mostly unintentional). Understanding the different URL variations that could exist can help you identify your own URLs with duplicated pages.
Tip: As you discover URLs that have duplicate content, take note of other aspects of your website URLs that could use optimization!
URL Variations
Variations in URLs can occur from session IDs, query parameters, and capitalizations. When a URL uses parameters that do not change the content on the page, it can end up creating a duplicated page.
For example: https://bluefrogdm.com/blog/local-seo-series/ and https://bluefrogdm.com/blog/local-seo-series/?source=ppc both lead to the exact same page, but are accessed by different URLs, thus causing a duplicate content page.
Session IDs work in a similar way. In order to keep track of the visitors on your site, you may use session IDs to learn what the user did while they were on the site, and where they went. In order to do so, the session ID is added to the URL of each page they click into. The added session ID creates a new URL to the same page and is thus considered duplicate content.
Capitalizations are often not added intentionally, but it is important to ensure your URLs are consistent and use lowercase letters. For example, bluefrogdm.com/blog and bluefrogdm.com/Blog would be considered duplicated pages.
HTTP vs HTTPS and www vs non-www
When you add SSL certificates to your site, you secure your website, which gives you the ability to use HTTPS instead of HTTP. However, this causes duplicate pages of your website to exist on each. Similarly, your website content is accessible from both www and non-www URLs.
The following URLs all lead to the exact same page, but would be considered completely different URLs to search engine crawlers:
https://bluefrogdm.com http://bluefrogdm.com
www.bluefrogdm.com bluefrogdm.com
Only one of the above versions should be accessible; all others should be redirected to the preferred version.
Scraped or Copied Content
When other websites “steal” content from another site, it is referred to as content scraping. If Google or other search engines cannot identify the original piece of content, they may end up ranking the page that was copied from your site.
Copied content often occurs for sites with products listed with manufacturer descriptions. If the same product is sold on multiple sites and all sites use the manufacturer descriptions, then duplicated content can be found on multiple pages across different sites.
Ways to Remove Duplicate Content
Removing duplicate content will help you ensure the correct page is accessible and indexed by search engine crawlers. However, you may not want to fully remove all types of duplicate content. There are some instances where you simply want to tell search engines which version is the original. Here are a few ways you can manage duplicate content across your site:
Rel = “canonical” tag
The rel = canonical attribute is a snippet of code that tells search engine crawlers that a page is a duplicated version of the specified URL. Search engines will then send all links and ranking power to the specified URL, as they will consider it the “original” piece of content.
One thing to note: using the rel = canonical tag will not remove the duplicated page from search results, it will simply tell search engine crawlers which one is the original and where the content metrics and link equity should go.
Rel = canonical tags are beneficial to use when the duplicated version does not need to be removed, such as URLs with parameters or trailing slashes.
Here is an example from a HubSpot blog post:
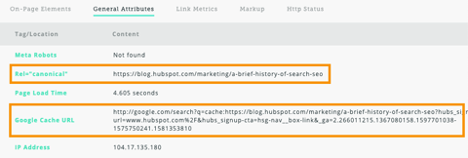
As you can see, HubSpot has indicated that the original version of the page is blog.hubspot.com/marketing/a-brief-history-of-search-seo. This tells search engines that the page view should be given to that URL, rather than the long URL with the tracking parameters at the end.
301 Redirects
Using a 301 redirect is the best option if you do not want the duplicated page to be accessible. When you implement a 301 redirect, it tells the search engine crawler that all the traffic and SEO values should go from Page A to Page B.
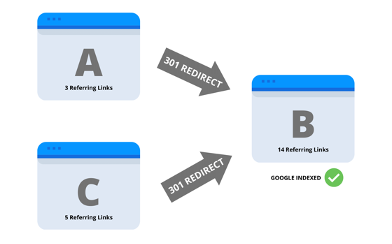
When deciding which page to keep, and which pages to redirect, look for the page that is the best performing and most optimized. When you take multiple pages that are competing for ranking positions and combine them into one piece of content, you will create a stronger and more relevant page that search engines and users will prefer.
301 redirects can help with more than just duplicate content, follow these tips to set up and use 301 redirects to help boost your SEO.
Dive further into SEO and local SEO by downloading the Local SEO Checklist!

Robots Meta Noindex, Follow Tag
The meta robots tag is a snippet of code you add into the HTML head of the page you want to exclude from search engine indices. When you add the code “content=noindex, follow”, you tell search engines to crawl the links on the page, but this also prevents them from adding those links to their indices.
The meta robots noindex tag is particularly beneficial in handling pagination duplicate content. Pagination occurs when content spans across multiple pages, thus resulting in multiple URLs. Adding the “noindex, follow” code to the pages will allow the search engine robots to crawl the pages, but will not rank the pages in search results.
Here’s an example of duplicate content as a result of pagination:
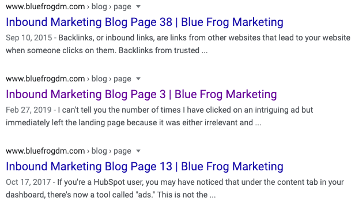
From the image above, you can see that the Blue Frog blog has multiple pages of content, which causes those pages to appear in search results. Adding the robots meta tag would allow these pages to still be crawled but would prevent them from appearing in search results.
Bonus Tips to Prevent Duplicate Content
To help prevent the creation of some duplicate content, ensure you are proactive about how your pages are set up. Here are two things you can do to combat duplicate content creation:
Internal Linking Consistency
A good internal linking strategy is important for building your SEO value on the page. However, it is important to ensure you are consistent with the structure of the URLs in your linking strategy.
For example, if you decide the canonical version of your homepage is www.bluefrogdm.com/, then all internal links to the homepage should be https://www.bluefrogdm.com/ rather than https://bluefrogdm.com/ (the difference being the absence of the www top level domain).
Maintain consistency with the following common URL variations:
- HTTP vs HTTPS
- www vs non-www
- Trailing slash: example.com vs example.com/
If one internal link uses a trailing slash, but another link to the same page does not, you will create duplicate content of the page.
Use Self-Referential Canonical Tag
To help prevent content scraping, you can add the rel=canonical meta tag that points to the URL the page is already on; this creates a self-canonical page. Adding the rel=canonical tag will tell search engines that the current page is the original piece of content.
When a site is copied, the HTML code is taken from the original piece of content and added to a different URL. If a rel=canonical tag is included in the HTML code, it will likely be copied to the duplicated site as well, thus preserving the original page as the canonical version. It is important to note that this is an added safeguard that will only work if the content scrapers copy that part of the HTML code.
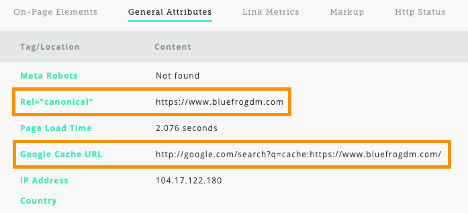
Blue Frog’s homepage contains a rel=canonical tag that points to the homepage URL. This tells search engines that this URL is the original, in case a content scraper attempts to duplicate the page for themselves.
Duplicate content is often not created intentionally but can indirectly harm your SEO value and ranking potential if left unattended. By finding and managing the duplicate content on your site, you can ensure search engine crawlers know exactly what to do when they encounter duplicated content from your site. The more proactive you are in the beginning, the less of an issue it will be in the long run.


